
Page 105 - FULL REPORT 30012024
P. 105
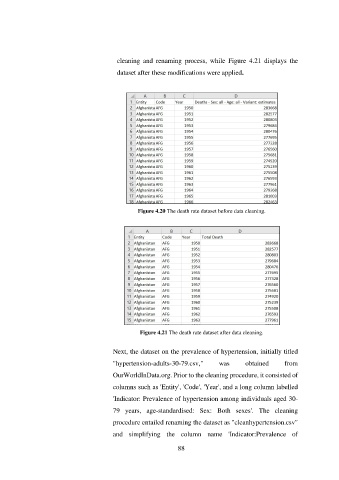
cleaning and renaming process, while Figure 4.21 displays the
dataset after these modifications were applied.
Figure 4.20 The death rate dataset before data cleaning.
Figure 4.21 The death rate dataset after data cleaning.
Next, the dataset on the prevalence of hypertension, initially titled
"hypertension-adults-30-79.csv," was obtained from
OurWorldInData.org. Prior to the cleaning procedure, it consisted of
columns such as 'Entity', 'Code', 'Year', and a long column labelled
'Indicator: Prevalence of hypertension among individuals aged 30-
79 years, age-standardised: Sex: Both sexes'. The cleaning
procedure entailed renaming the dataset as "cleanhypertension.csv"
and simplifying the column name 'Indicator:Prevalence of
88