
Page 66 - E-Skripsi Analisis Sentimen Terhadap Aplikasi Sapawarga Jabar Super Apps Pada Ulasan Google Play Store
P. 66
3.3.3 Pemodelan Data
Pada tahap selanjutnya pemodelan data dengan cara mempelajari
klasifikasi pada data latih menggunakan Support Vector Mahine (SVM). Peneliti
membagi data latih (test) dan data uji (train) dengan melakukan beberapa
perbandingan untuk menghasilkan akurasi paling tinggi. Adapun rasio yang
digunakan yaitu 90:10, 80:20, 70:30, dan 60:40.
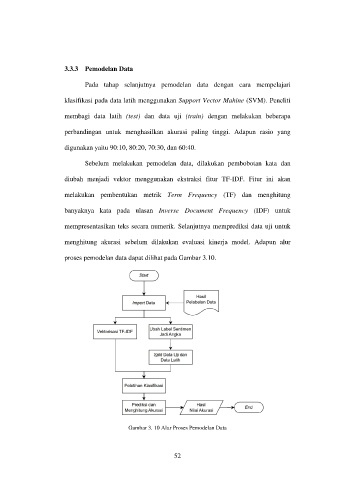
Sebelum melakukan pemodelan data, dilakukan pembobotan kata dan
diubah menjadi vektor menggunakan ekstraksi fitur TF-IDF. Fitur ini akan
melakukan pembentukan metrik Term Frequency (TF) dan menghitung
banyaknya kata pada ulasan Inverse Document Frequency (IDF) untuk
mempresentasikan teks secara numerik. Selanjutnya memprediksi data uji untuk
menghitung akurasi sebelum dilakukan evaluasi kinerja model. Adapun alur
proses pemodelan data dapat dilihat pada Gambar 3.10.
Gambar 3. 10 Alur Proses Pemodelan Data
52