
Page 7 - ClickHouse--day01--架构原理和表引擎详解(2)
P. 7
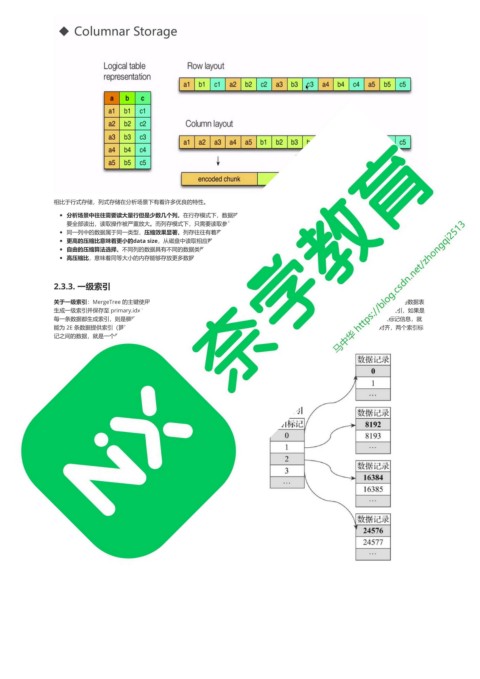
相比于行式存储,列式存储在分析场景下有着许多优良的特性。
分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也
要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
2.3.3. 一级索引
关于一级索引:MergeTree 的主键使用 PRIMARY KEY 定义,待主键定义之后,MergeTree 会依据 index_granularity 间隔(默认 8192 行),为数据表
生成一级索引并保存至 primary.idx 文件内。一级索引是稀疏索引,意思就是说:每一段数据生成一条索引记录,而不是每一条数据都生成索引,如果是
每一条数据都生成索引,则是稠密索引。稀疏索引的好处,就是少量的索引标记,就能记录大量的数据区间位置信息,比如不到 24414 条标记信息,就
能为 2E 条数据提供索引(算法:200000000 / 8192)。在 ClickHouse 中,一级索引常驻内存。总的来说:一级索引和标记文件一一对齐,两个索引标
记之间的数据,就是一个数据区间,在数据文件中,这个数据区间的所有数据,生成一个压缩数据块。