
Page 3 - Paper Title (use style: paper title)
P. 3
̅̅̅̅
̅̅̅̅
∑ n i=1 x i y i ∑ ∈ ( , − )×( , − )
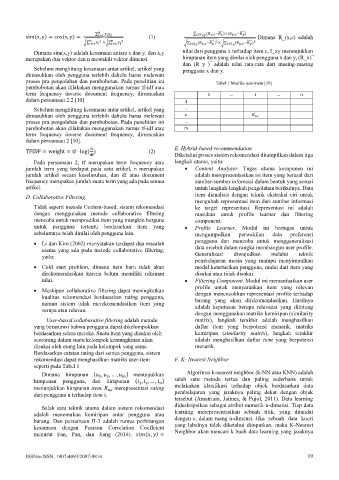
sim(x, y) = cos(x, y) = (1) Dimana R_(x,c) adalah
2
̅̅̅̅ 2
√∑ n x i ×√∑ n 2 ̅̅̅̅ 2 ( , − )
i=1 i=1 y i √∑ ∈ ( , − ) ×√ ∑ ∈
Dimana sim(x,y) adalah kesamaan antara x dan y. dan x,y nilai dari pengguna x terhadap item c, I_xy menunjukkan
merupakan dua vektor dan n mewakili vektor dimensi. himpunan item yang dinilai oleh pengguna x dan y, (R_x) ̅
dan (R_y ) ̅ adalah nilai rata-rata dari masing-masing
Sebelum menghitung kesamaan antar artikel, artikel yang pengguna x dan y.
dimasukkan oleh pengguna terlebih dahulu harus melewati
proses pra pengolahan dan pembobotan. Pada penelitian ini Tabel 1 Matriks user-item [10]
pembobotan akan dilakukan menggunakan rumus tf-idf atau
term frequency inverse document frequency, dirumuskan 1 … i … n
dalam persamaan 2.2 [10] 1
Sebelum menghitung kesamaan antar artikel, artikel yang …
dimasukkan oleh pengguna terlebih dahulu harus melewati u ,
proses pra pengolahan dan pembobotan. Pada penelitian ini …
pembobotan akan dilakukan menggunakan rumus tf-idf atau m
term frequency inverse document frequency, dirumuskan
dalam persamaan 2 [10].
n
TFIDF = weight = tf ∙ log ( ) (2) E. Hybrid-based recommendation
df Diketahui proses sistem rekomendasi ditampilkan dalam tiga
Pada persamaan 2, tf merupakan term frequency atau langkah utama, yaitu:
jumlah term yang terdapat pada satu artikel, n merupakan Content Analyzer. Tugas utama komponen ini
jumlah artikel secara keseluruhan, dan df atau document adalah merepresentasikan isi item yang berasal dari
frequency merupakan jumlah suatu term yang ada pada semua sumber-sumber informasi dalam bentuk yang sesuai
artikel. untuk langkah-langkah pengolahan berikutnya. Data
D. Collaborative Filtering item dianalisis dengan teknik ekstraksi ciri untuk
mengubah representasi item dari sumber informasi
Tidak seperti metode Content-based, sistem rekomendasi ke target representasi. Representasi ini adalah
dengan menggunakan metode collaborative filtering masukan untuk profile learner dan filtering
mencoba untuk memprediksi item yang mungkin berguna component.
untuk pengguna tertentu berdasarkan item yang Profile Learner. Modul ini bertugas untuk
sebelumnya telah dinilai oleh pengguna lain. mengumpulkan perwakilan data preferensi
pengguna dan mencoba untuk menggeneralisasi
Li dan Kim (2002) menyatakan terdapat dua masalah
utama yang ada pada metode collaborative filtering, data ersebut dalam rangka membangun user profile.
yaitu: Generalisasi diwujudkan melalui teknik
pembelajaran mesin yang mampu menyimpulkan
Cold start problem, dimana item baru tidak akan model ketertarikan pengguna, mulai dari item yang
direkomendasikan karena belum memiliki rekaman disukai atau tidak disukai.
nilai. Filtering Component. Modul ini memanfaatkan user
profile untuk menyarankan item yang relevan
Meskipun collaborative filtering dapat meningkatkan
kualitas rekomendasi berdasarkan rating pengguna, dengan mencocokkan representasi profile terhadap
barang yang akan direkomendasikan. Hasilnya
namun sistem tidak merekomendasikan item yang
serupa atau relevan. adalah keputusan berupa relevansi yang dihitung
dengan menggunakan matriks kemiripan (similarity
User-based collaborative filtering adalah metode matrix), langkah terakhir adalah menghasilkan
yang berasumsi bahwa pengguna dapat dikelompokkan daftar item yang berpotensi menarik. matriks
berdasarkan selera mereka. Suatu item yang disukai oleh kemiripan (similarity matrix), langkah terakhir
seseorang dalam suatu kelompok kemungkinan akan adalah menghasilkan daftar item yang berpotensi
disukai oleh orang lain pada kelompok yang sama. menarik.
Berdasarkan catatan rating dari semua pengguna, sistem
rekomendasi dapat menghasilkan matriks user-item F. K- Nearest Neighbor
seperti pada Tabel 1
Dimana himpunan { , , … , } menunjukkan Algoritma k-nearest neighbor (k-NN atau KNN) adalah
2
1
himpunan pengguna, dan himpunan { , , … , } salah satu metode tertua dan paling sederhana untuk
2
1
menunjukkan himpunan item. merepresentasi rating melakukan klasifikasi terhadap objek berdasarkan data
,
dari pengguna u terhadap item i. pembelajaran yang jaraknya paling dekat dengan objek
tersebut (Amatriain, Jaimes, & Pujol, 2011). Data learning
Salah satu teknik utama dalam sistem rekomendasi dideskripsikan sebagai atribut numerik n-dimensi. Tiap data
adalah menemukan kemiripan antar pengguna atau learning merepresentasikan sebuah titik, yang ditandai
barang. Dan persamaan II-3 adalah rumus perhitungan dengan c, dalam ruang n-dimensi. Jika sebuah data kueri
kesamaan dengan Pearson Correlation Coeffcient yang labelnya tidak diketahui diinputkan, maka K-Nearest
menurut Fan, Pan, dan Jiang (2014). ( , ) = Neighbor akan mencari k buah data learning yang jaraknya
ISSN/e-ISSN: 1907-4093/2087-9814 19