
Page 189 - 데이터과학 무엇을 하는가? 전자책
P. 189
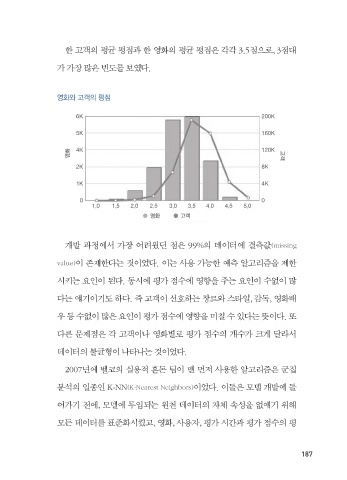
한 고객의 평균 평점과 한 영화의 평균 평점은 각각 3.5점으로, 3점대
가 가장 많은 도를 보였다.
영화와 고 의
6K 200K
5K 160K
영화 4K 120K 고
2K 8K
1K 4K
0 0
1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
영화 고
개발 과정에서 가장 어려웠던 점은 99%의 데이터에 결측 (missing
value)이 존재한다는 것이었다. 이는 사용 가능한 예측 알고리즘을 제한
시키는 요인이 된다. 동시에 평가 점수에 영향을 주는 요인이 수없이 많
다는 얘기이기도 하다. 즉 고객이 선호하는 장르와 스타일, 감 , 영화배
우 등 수없이 많은 요인이 평가 점수에 영향을 미 수 있다는 뜻이다. 또
다른 문제점은 각 고객이나 영화별로 평가 점수의 개수가 크게 달라서
데이터의 불균형이 나타나는 것이었다.
2007년에 코의 실용적 이 먼저 사용한 알고리즘은 집
분석의 일종인 K-NN(K-Nearest Neighbors)이었다. 이들은 모델 개발에 들
어가기 전에, 모델에 투입되는 원천 데이터의 자체 속성을 없애기 위해
모든 데이터를 표준화시 고, 영화, 사용자, 평가 시간과 평가 점수의 평
187