
Page 297 - 데이터과학 무엇을 하는가? 전자책
P. 297
데이터 전 리 데이터 이산화
데이터 이산화 작업이란 연속 변수를 구간으로 개 이산 변수로
만드는 것을 말한다. 이산화시키는 방법은 히스토그 분석, 그룹화
(clustering) 분석, 엔트로피(Entropy)식 이산화, 세분(segmentation)식 그룹
화를 이용하거나 단계별 일반화 방법을 사용한다.
데이터 전처리가 어느 정도 마무리되면 분석 주제에 대한 현황과 조사
연구한 내용들을 정리하여 보고서를 작성하면 된다. 문제는 선택이다. 예
를 들어 여러 가지 데이터 이산화 방법 중 어떤 방법이 가장 적절할지 선
택하는 것이 관건이다. 데이터의 속성에 따라 다르고 분석 목적이나 분석
가의 경험에 따라 선택을 달리 할 수 있다. 이처럼 데이터 전처리는 같은
데이터를 두고 경우에 따라 다양한 방식으로 다르게 진행될 수 있다.
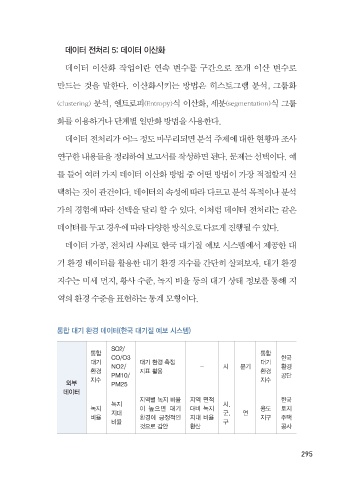
데이터 가공, 전처리 사례로 한국 대기질 예보 시스템에서 제공한 대
기 환경 데이터를 활용한 대기 환경 지수를 간단히 살펴보자. 대기 환경
지수는 미세 먼지, 황사 수준, 지 비율 등의 대기 상태 정보를 통해 지
역의 환경 수준을 표현하는 통계 모형이다.
통합 대기 환 데이터 한국 대기질 예보 시스템
SO2/
통합 CO/O3 통합 한국
대기 NO2/ 대기 환경 정 - 시 분기 대기 환경
환경 PM10/ 지표 활용 환경 공단
지수 지수
부 PM25
데이터
지역별 지 비율 지역 면적 한국
지 시,
지 이 으면 대기 대비 지 용도 토지
지대 군, 연
비율 환경에 정적인 지대 비율 지구 주택
비율 구
으로 감안 환산 공사
295