
Page 233 - Data Science Algorithms in a Week
P. 233
Managing Overcrowding in Healthcare using Fuzzy Logic 217
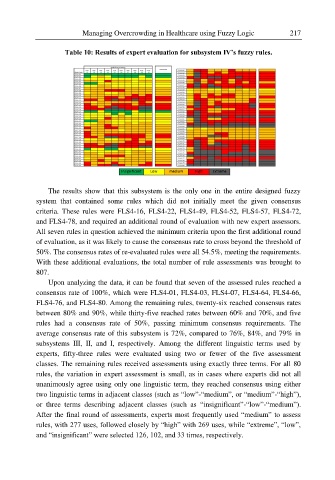
Table 10: Results of expert evaluation for subsystem IV’s fuzzy rules.
The results show that this subsystem is the only one in the entire designed fuzzy
system that contained some rules which did not initially meet the given consensus
criteria. These rules were FLS4-16, FLS4-22, FLS4-49, FLS4-52, FLS4-57, FLS4-72,
and FLS4-78, and required an additional round of evaluation with new expert assessors.
All seven rules in question achieved the minimum criteria upon the first additional round
of evaluation, as it was likely to cause the consensus rate to cross beyond the threshold of
50%. The consensus rates of re-evaluated rules were all 54.5%, meeting the requirements.
With these additional evaluations, the total number of rule assessments was brought to
807.
Upon analyzing the data, it can be found that seven of the assessed rules reached a
consensus rate of 100%, which were FLS4-01, FLS4-03, FLS4-07, FLS4-64, FLS4-66,
FLS4-76, and FLS4-80. Among the remaining rules, twenty-six reached consensus rates
between 80% and 90%, while thirty-five reached rates between 60% and 70%, and five
rules had a consensus rate of 50%, passing minimum consensus requirements. The
average consensus rate of this subsystem is 72%, compared to 76%, 84%, and 79% in
subsystems III, II, and I, respectively. Among the different linguistic terms used by
experts, fifty-three rules were evaluated using two or fewer of the five assessment
classes. The remaining rules received assessments using exactly three terms. For all 80
rules, the variation in expert assessment is small, as in cases where experts did not all
unanimously agree using only one linguistic term, they reached consensus using either
two linguistic terms in adjacent classes (such as “low”-“medium”, or “medium”-“high”),
or three terms describing adjacent classes (such as “insignificant”-“low”-“medium”).
After the final round of assessments, experts most frequently used “medium” to assess
rules, with 277 uses, followed closely by “high” with 269 uses, while “extreme”, “low”,
and “insignificant” were selected 126, 102, and 33 times, respectively.