
Page 58 - FULL REPORT 30012024
P. 58
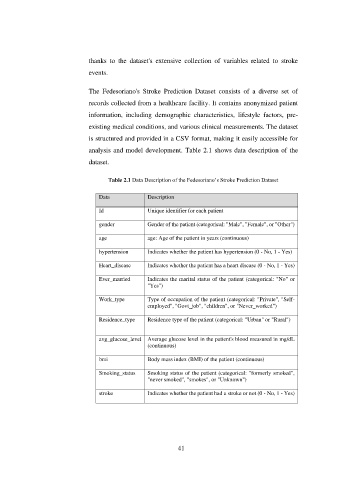
thanks to the dataset's extensive collection of variables related to stroke
events.
The Fedesoriano's Stroke Prediction Dataset consists of a diverse set of
records collected from a healthcare facility. It contains anonymized patient
information, including demographic characteristics, lifestyle factors, pre-
existing medical conditions, and various clinical measurements. The dataset
is structured and provided in a CSV format, making it easily accessible for
analysis and model development. Table 2.1 shows data description of the
dataset.
Table 2.1 Data Description of the Fedesoriano’s Stroke Prediction Dataset
Data Description
Id Unique identifier for each patient
gender Gender of the patient (categorical: "Male", "Female", or "Other")
age age: Age of the patient in years (continuous)
hypertension Indicates whether the patient has hypertension (0 - No, 1 - Yes)
Heart_disease Indicates whether the patient has a heart disease (0 - No, 1 - Yes)
Ever_married Indicates the marital status of the patient (categorical: "No" or
"Yes")
Work_type Type of occupation of the patient (categorical: "Private", "Self-
employed", "Govt_job", "children", or "Never_worked")
Residence_type Residence type of the patient (categorical: "Urban" or "Rural")
avg_glucose_level Average glucose level in the patient's blood measured in mg/dL
(continuous)
bmi Body mass index (BMI) of the patient (continuous)
Smoking_status Smoking status of the patient (categorical: "formerly smoked",
"never smoked", "smokes", or "Unknown")
stroke Indicates whether the patient had a stroke or not (0 - No, 1 - Yes)
41