
Page 59 - Data Science Algorithms in a Week
P. 59
Using Deep Learning to Configure Parallel Distributed Discrete-Event Simulators 43
(i.e., to obtain the right architecture, and one hundred for testing (i.e., to test the DBN
developed).
The training session for a DBN was accomplished. There are three principles for
training DBNs:
1. Pre-training one layer at a time in a greedy way;
2. Using unsupervised learning at each layer in a way that preserves information from
the input and disentangles factors of variation;
3. Fine-tuning the whole network with respect to the ultimate criterion of interest
We have used method No. 2 for this research because is the most recognized one
(Mohamed et al., 2011). In addition, we developed several standard backpropagation
networks with only one hidden layer and they never converged with the training data.
Results
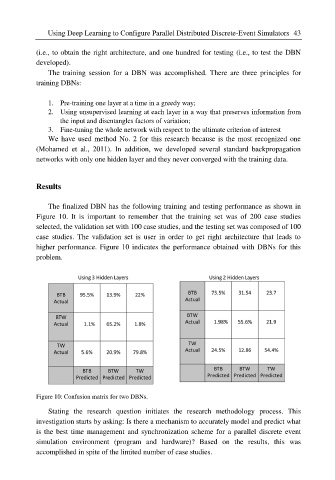
The finalized DBN has the following training and testing performance as shown in
Figure 10. It is important to remember that the training set was of 200 case studies
selected, the validation set with 100 case studies, and the testing set was composed of 100
case studies. The validation set is user in order to get right architecture that leads to
higher performance. Figure 10 indicates the performance obtained with DBNs for this
problem.
Figure 10: Confusion matrix for two DBNs.
Stating the research question initiates the research methodology process. This
investigation starts by asking: Is there a mechanism to accurately model and predict what
is the best time management and synchronization scheme for a parallel discrete event
simulation environment (program and hardware)? Based on the results, this was
accomplished in spite of the limited number of case studies.